We have benchmarked KeystoneML against state-of-the-art performance achieved by other learning systems on a number of end-to-end benchmarks. In order to make these comparisons, we faithfully recreated learning pipelines as described by the benchmark authors, and run them on Amazon c2.4xlarge machines. The intent of these benchmarks is to show that end-to-end applications can be written and executed efficiently in KeystoneML.
Here we report the time taken by KeystoneML, the time taken by the competing systems, number of CPU cores (or number of GPUs) allocated to each system, total wall-clock speedup. By efficiently leveraging cluster resources, KeystoneML is able to run tasks an order of magnitude faster than highly specialized single-node systems. Meanwhile, on the TIMIT task, we’re able to match state-of-the art performance (and nearly match the runtime) on an IBM BlueGene supercomputer using a fraction of the resources.
Each of the example pipelines below can be found in the KeystoneML source code.
| Dataset | KeystoneML Accuracy |
Reported Accuracy |
KeystoneML Time (m) |
Reported Time (m) |
KeystoneML CPU Cores |
Reported CPU Cores |
Speedup Over Reported |
|---|---|---|---|---|---|---|---|
| Amazon Reviews1 | 91.6% | N/A | 3.3 | N/A | 256 | N/A | N/A |
| TIMIT2 | 66.1% | 66.3% | 138 | 120 | 512 | 4096 | 0.87x |
| ImageNet3 | 67.4% | 66.6% | 270 | 5760 | 800 | 16 | 21x |
| VOC4 | 57.2% | 59.2% | 7 | 87 | 256 | 16 | 12x |
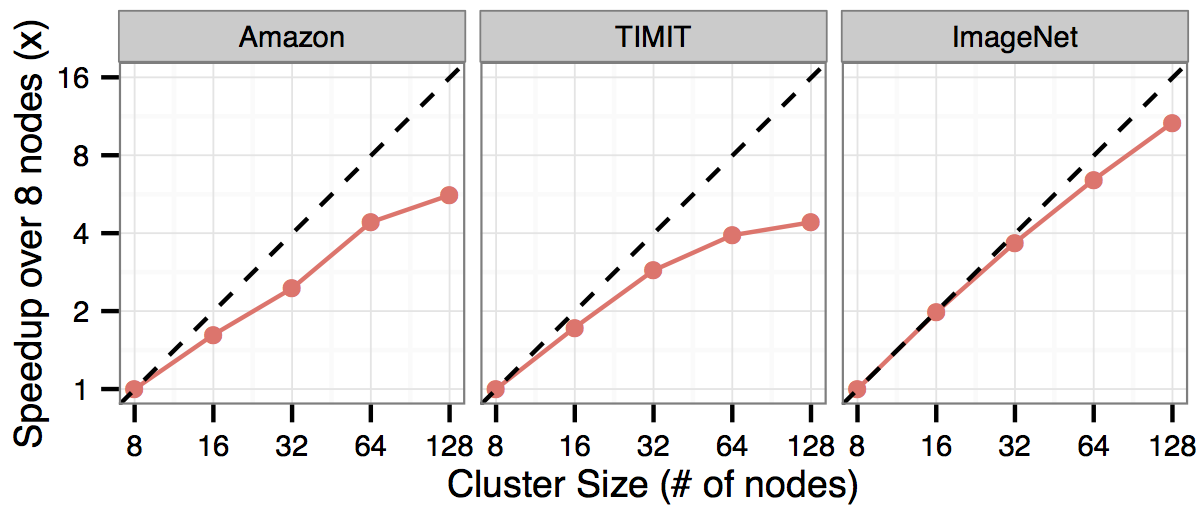
Additionally, we’ve tested KeystoneML for its scalability to clusters with hundreds of nodes and thousands of cores. Here, we show the speedup of three pipelines (Amazon Reviews, TIMIT, and ImageNet) over 8 nodes. Ideal speedup is shown with the dotted line. KeystoneML is able to achieve near linear speedup as we add more nodes because of its use of communication-avoiding algorithms during featurization and model training.